

Google Attributes Significant Cloud Outage to API Management Complications








Google has attributed a significant disruption in its cloud services to an issue with API management, which resulted in widespread outages affecting numerous platforms globally.
The outage, which began at approximately 10:49 AM ET and lasted until 3:49 PM ET, impacted millions of users for over three hours. The services affected included Gmail, Google Calendar, Google Chat, Google Cloud Search, Google Docs, Google Drive, Google Meet, Google Tasks, Google Voice, Google Lens, Discover, and Voice Search.
This incident not only disrupted Google’s own services but also had a ripple effect on third-party platforms that utilize Google Cloud, including significant services such as Spotify, Discord, Snapchat, NPM, Firebase Studio, and various Cloudflare functionalities dependent on the Workers KV key-value store.
In a formal acknowledgment, Google extended its apologies to all users and their customers impacted by the outage, reinforcing its commitment to improving service reliability. The company is actively working on a detailed incident report but has already provided insights into the root cause: an increase in 503 errors for external API requests during the outage period.
According to Google, the incident stemmed from a failure in its Google Cloud API management platform, triggered by invalid data. The inefficiencies in testing and error-handling protocols delayed the discovery and correction of this issue.
Initial analyses reveal that the problem originated from an erroneous automated quota update within the API management system, which was globally distributed and caused the rejection of external API requests. Recovery efforts involved bypassing the problematic quota check, resulting in a restoration of service in most regions within approximately two hours. However, the database handling quota policies in the us-central1 region faced additional strain, leading to prolonged recovery times in that area, with residual impacts evident for up to an hour thereafter.
Impact on Cloudflare Services
After restoring its affected services, Cloudflare confirmed that the incident was not tied to any security breaches and that data integrity had been maintained. The outage was found to be caused by failures in the underlying storage infrastructure utilized by its Workers KV service, which is integral for configuration, authentication, and asset delivery across its affected services.
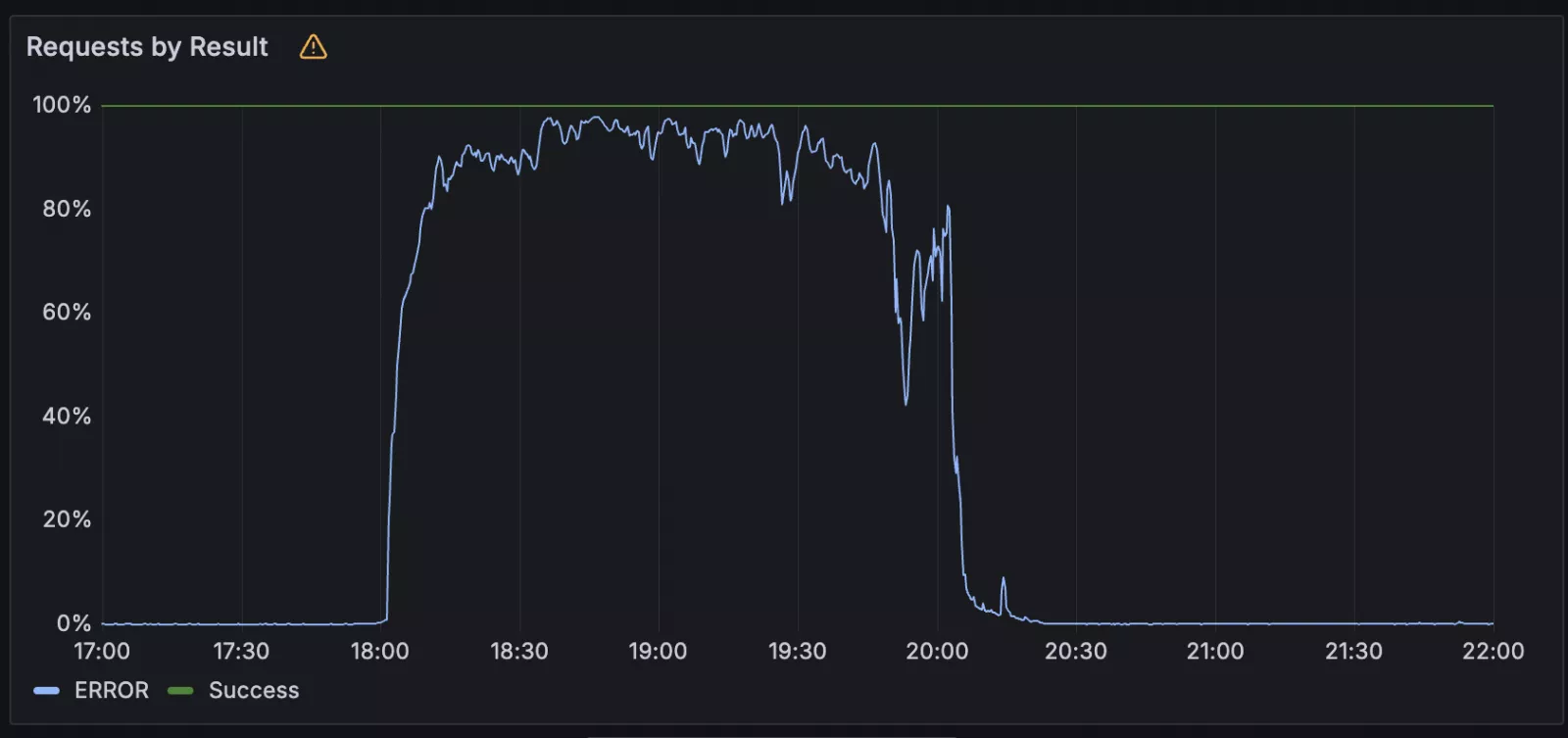
Part of the critical infrastructure relied on a third-party cloud provider that experienced an outage, directly impairing the availability of Cloudflare’s KV service. Despite the uncertainty about the identity of the cloud provider involved, a representative from Cloudflare indicated that only those Cloudflare services that depended on Google Cloud were affected.
As a proactive measure following the incident, Cloudflare announced plans to migrate the KV central store to its own R2 object storage, thereby reducing reliance on external providers and minimizing the possibility of similar future disruptions.